K15t Software recently released Backbone Issue Sync for JIRA Data Center. As the technical lead in charge of this compatibility implementation, I'd like to take you behind the scenes and share with you how we solved some tricky development challenges.
First off, you'll need to keep in mind what a typical JIRA Data Center installation looks like. Usually, multiple JIRA servers are configured so they identify as part of a JIRA Data Center with a commonly shared database, cache and home folder (on a network drive for example). On top of that, a load balancer takes care of spreading requests evenly among JIRA nodes.

A typical JIRA Data Center installation
Running background tasks on just one Data Center node
Keeping in mind that Backbone runs different background tasks in order to synchronize issue data between separate JIRA instances, it quickly became obvious these tasks had to run on just one Data Center node. If I'd simply installed Backbone without making any adaptations, the load balancer would have distributed these background tasks, causing issue data changes to be synchronized multiple times.
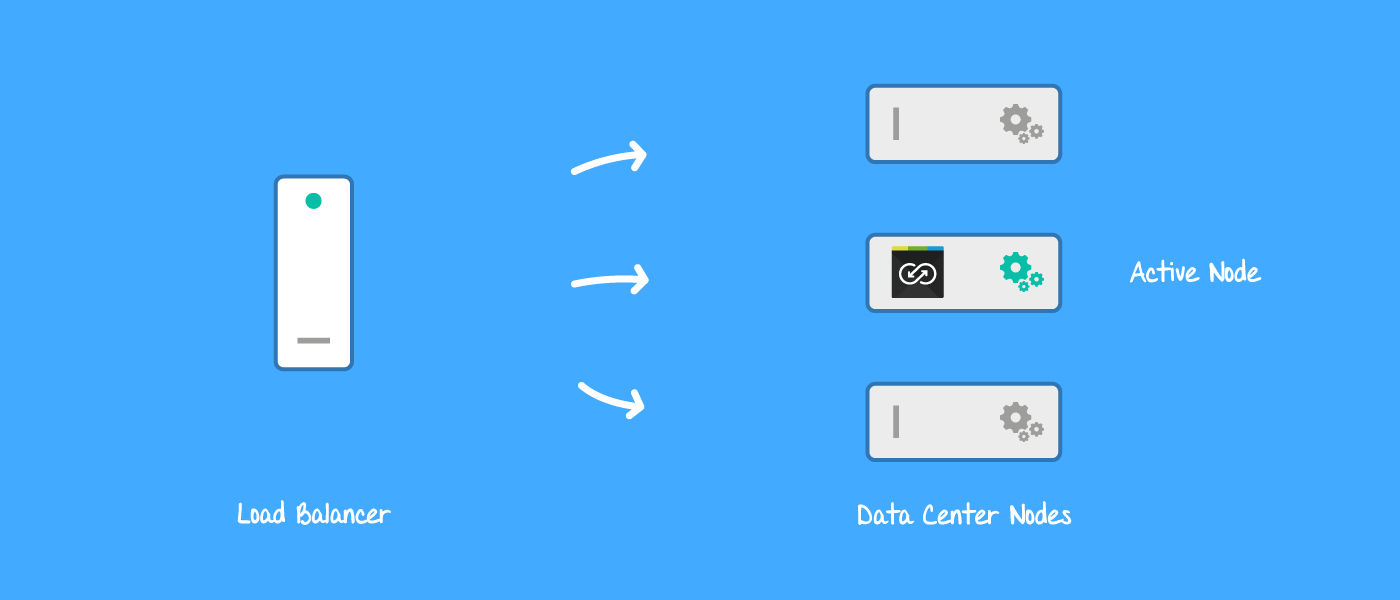
Backbone for JIRA Data Center synchronization tasks run on one Data Center node
Obviously this needed to be avoided, as multiple synchronizations could result in issue data (such as comments and attachments) being duplicated. In order to simplify the problem, I decided to force all Backbone tasks to run on just one JIRA Data Center node – called an active node
After consulting Atlassian's development guide, a cluster lock seemed to be the solution. I would simply have to activate a cluster lock, allowing Backbone tasks to run on different threads within the same node. However, I have since learned (the hard way) that cluster locks are only meant to be used for short periods of time and can only be acquired by one thread. As soon as another thread in the same node tries to retrieve the lock, it would be blocked – resulting in a deadlock and all other Backbone tasks not being executed.
So instead of using a cluster lock, I came up with the idea of saving a node's ID in the database to identify the active node. On startup, every node would check if an ID was already stored in the database. If this wasn't the case, the inquiring node would add its ID, turning that node into the active node: and Backbone tasks would start running. This way I was able to ensure that only the one node would run Backbone tasks. In the end, I still used a cluster lock to safeguard against multiple nodes simultaneously trying to become the active node.
Now, you might be wondering what happens if the active node goes down. After all, isn't the entire idea of node clustering to avoid any downtime?
Active node down – synchronization must go on
Of course, if you use JIRA Data Center, you also want Backbone Issue Sync to keep synchronizing your issue data, even if the active node goes offline. You'd expect another node to take over and in turn become the new active node. Basically, that's exactly what happens.
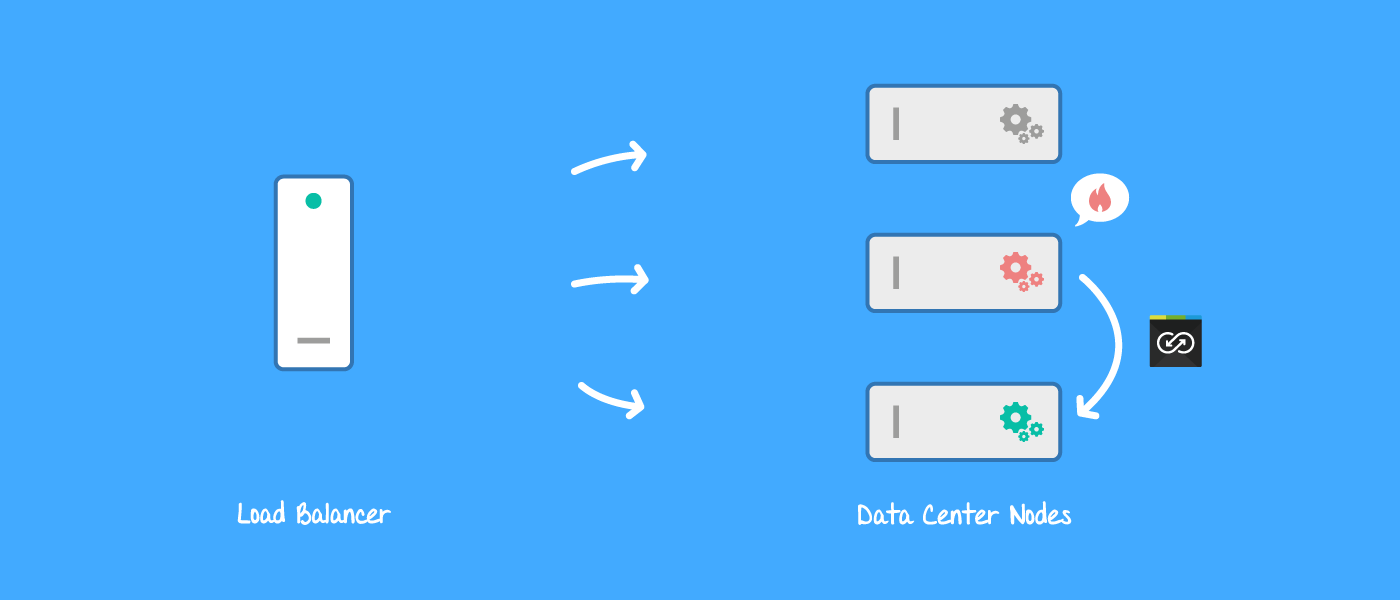
Synchronization tasks switch to another node when problems on the active node occur
In order for another node to recognize that the active node has failed and needs to be replaced, it needs to be listening and aware of the active node. To accomplish this, a background task runs on every node (except the active node), which looks up the active node ID on the database and then continuously examines if that node is still running. The JIRA ClusterManager makes this possible. The findLiveNodes() operation reports on all live nodes of a specific JIRA Data Center environment. If the active node isn't live anymore another will replace it and take over all synchronization tasks.
Getting the active node's status information
Backbone's UI displays status information about which integration is running at the moment and when the last change was sent for example. JIRA Data Center complicates the retrieval process of these status updates because the load balancer distributes requests among nodes and prevents direct communication with the active node. And yet, only the active node has information that needs to be retrieved. I had to find a way to relay Backbone status information to every node.
First, I thought about sending a ClusterMessage to the active node, which could in turn respond with the requested details. However, this method would take too long to run to be a viable option. So instead of retrieving data on demand, the active node now saves status updatesmto a place all nodes have access to – the cache. JIRA manages the cache across all Data Center nodes and accessing it is faster than obtaining database information.
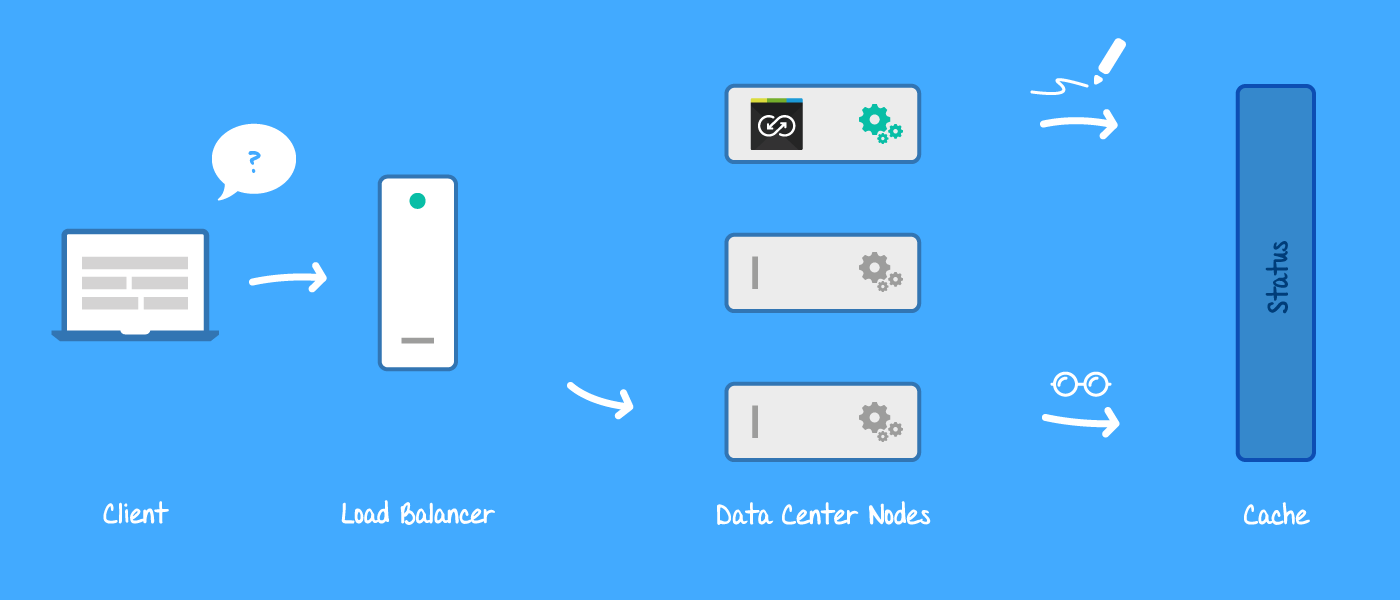
Example of how status information is retrieved through the Data Center's cache
So now, every Backbone status request from the UI is simply answered by any node looking up the corresponding cache entry.
Intentionally stopping the Backbone integration
The previously described challenge of addressing the right node also exists if you want to intentionally stop an actively running Backbone integration. Without a solution I couldn't be sure that the UI request was being directed to active node.
Perhaps this time around, ClusterMessages would actually work. Unfortunately, they are limited to 255 characters and I wanted to transport additional data along with the action. I had also read about Confluence cluster events which are able to create an event in one node and listen for events in other nodes. Sounded like the perfect fit. Alas, cluster events aren't available for JIRA and so I ended up using the cache again. As the cache worked just fine for transporting status data across Data Center nodes, I figured I could probably also add a CacheEntryListener.
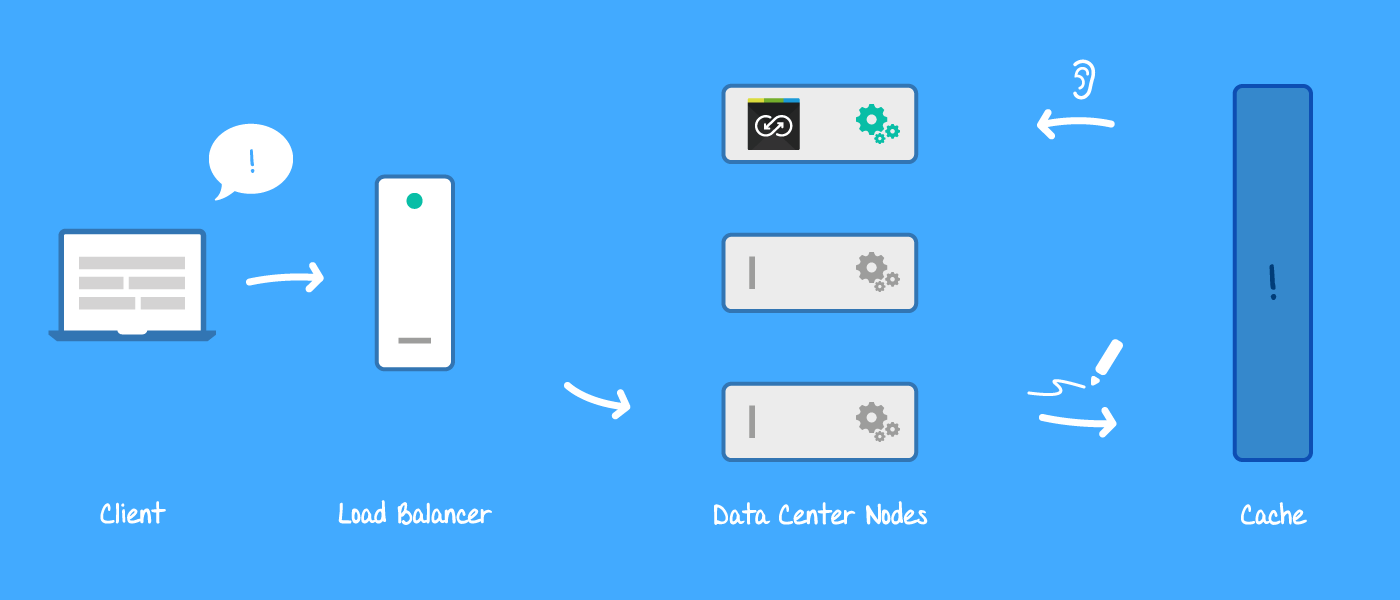
Example of how commands are directed to the active node
This way any node can write a Backbone command to the cache, and the active node executes it because it registered a CacheEntryListener. In principle this works as follows:
-
A node receives a Backbone request and adds this event to the cache.
-
The CacheEntryListener of the active node is notified and the active node executes the corresponding action.
-
In order to inform the client of its request status, the same approach is used as when the client sends a status update request. The cache is updated by the active node and other nodes can redirect the information to the client.
Remember to introduce unique IDs for every kind of request/event if you want to implement this approach.
All challenges mastered?
Of course, there are many more daunting aspects to developing an add-on for JIRA Data Center – one of which is setting up a JIRA Data Center test environment – but that's another blog post in the making. I hope this behind-the-scenes look at Backbone for JIRA Data Center's development helps you better understand how our JIRA issue data synchronization add-on works.
Please feel free to leave a comment or ask a question in the comments below. I'd be happy to discuss these with you.